
Yesterday via the Amazon blog we learned that the company has been working on a neural TTS that can model speaking styles with only a few hours of recordings. Among the problems in speech synthesis is the lack of tone and emotion. Finding correct intonation, stress, and duration from written text is probably the most challenging problem for years to come (per research in the Helsinki University of Technology).
The way you customize a synthesized speech today is through SSML, a speech markup language. SSML allows configuring prosody, emphasis and the actual voice used. The problem is that people change their speaking style depending on context and the emotional state of the person. What Amazon is saying in this announcement is that their latest TTS can learn a newscaster style from just a few hours of training, which it’s significant because with their previous model tens of hours were required.
This advance paves the way for Alexa and other services to adopt different speaking styles in different contexts, improving customer experiences.
The same way the neural model might work for newscaster style might work for other styles. Amazon also said they created a news-domain voice.
Listeners rated neutral NTTS more highly than concatenative synthesis, reducing the score discrepancy between human and synthetic speech by 46%.
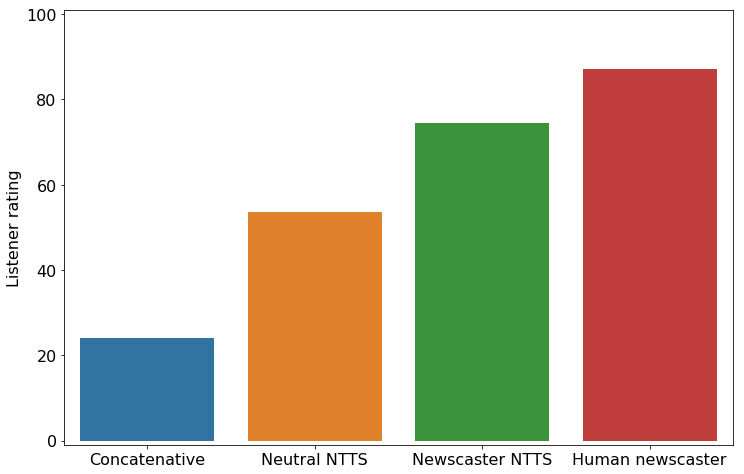
Let’s listen to the female voice with the newscaster style and judge for yourselves.
Very realistic news style. Isn’t?
It is very timely to bring up the results of the Reuters and Oxford report:
The Future of Voice and the implications for news. (I expanded on this on our last newsletter, subscribe). According to the report, consumers love smart speakers, they don’t love news from smart speakers. One of the main reasons the report concluded is Synthesized voices are hard to listen for many users.
The report also concluded that news updates are among the least valued features in smart speakers.
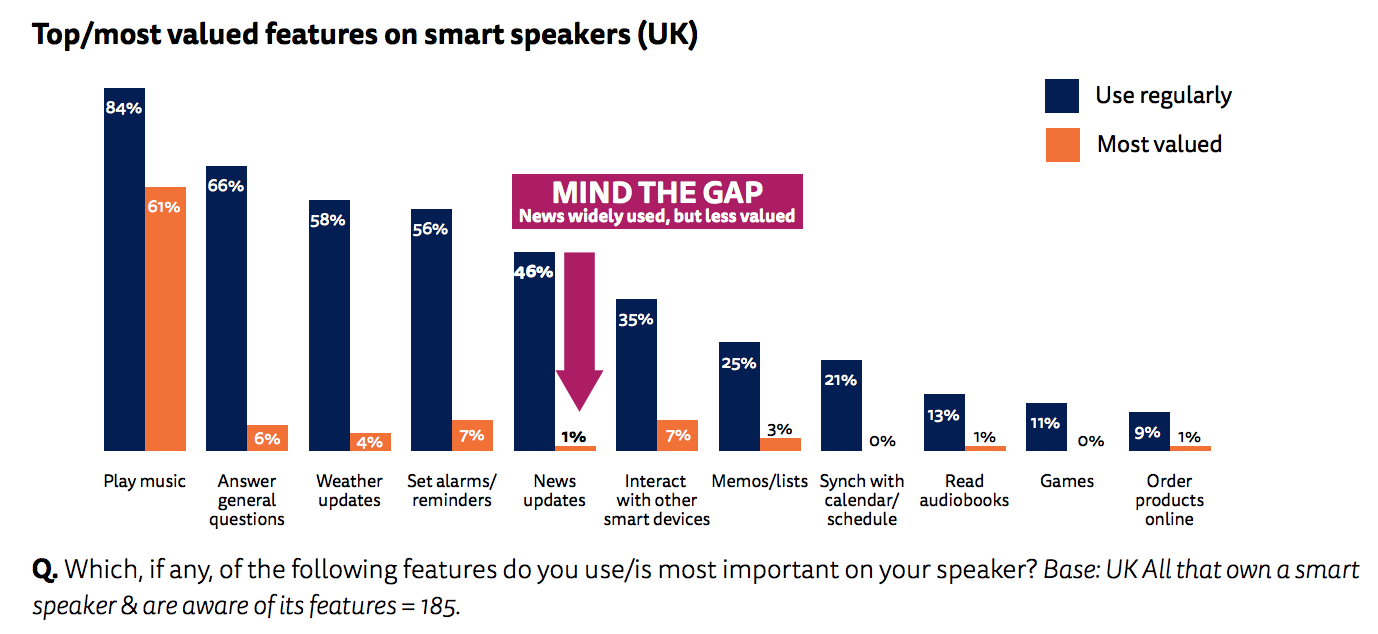
Additional points:
This new development of neural TTS by Amazon could mean more options of customization for brands looking to get a unique persona and voice in smart devices. Definitely, this is a very well received improvement in TTS.
I get more and more interested in synthesized speech every day as I realized is going to be a fundamental part of the future. That future might not be that far off: last week Chinese News Agency Xinhua announced the “world first” TV anchor at the World Internet Conference. The anchor features a virtual AI controlled avatar powered by synthetic speech.
The Revolution will be synthesized, my friends.
Thank you for listening, you have a great day. As always you can find me on Twitter as @voicefirstlabs or Instagram as @voicefirstweekly.